تکنولوژی Memory RAS چیست؟ انواع و کاربرد آن در سرورهای پرولینت

خرابیهای ماژولهای حافظه – در صورت عدم اصلاح – میتوانند منجر به مشکلات عملکردی یا حتی از کار افتادن سرور شود. با افزایش حجم حافظه در سرورهای مدرن، احتمال بروز خرابی در ماژولهای حافظه نیز افزایش مییابد. از آنجایی که خرابی حافظه در کنار خرابیهای ذخیرهسازی، از شایعترین مشکلات سرورها به شمار میروند، سرورهای نسل ۱۱ HPE ProLiant از پردازندههای مقیاسپذیر جدیدتری در مقایسه با نسل قبل پشتیبانی میکنند که مجموعهای جامع از ویژگیها مثل اطمینانپذیری، دسترسپذیری و سرویسدهی (RAS) حافظه را ارائه میدهند. این قابلیتها به دستههای زیر تقسیم میشوند:
- تشخیص و تصحیح خطا
- افزونگی و انعطاف پذیری
- نگهداری سیستم
این مقاله به بررسی اجمالی برخی از کاربردیترین فناوریهای Memory RAS برای سرورهای نسل ۱۱ پرولیانت اچ پی، ویژگیهای آنها، حداقل الزامات و نحوه فعالسازیشان میپردازد. این اطلاعات به شما در انتخاب مناسبترین فناوریهای Memory RAS متناسب با حجم کاری و نیازمندیهای سطح خدمات مرکز داده، به ویژه برای بارهای کاری حساس تجاری، کمک میکند. اگر تمایل به آشنایی با قابلیت Memory RAS دارید و دوست دارید در مورد ویژگی های جدید در حافظه های DDR5 RAS اطلاعاتی کسب کنید و بدانید که اساسا چرا به حافظه RAS نیاز داریم، این مقاله را از دست ندهید.
فروش سرور اچ پی در نتسا با گارانتی معتبر
فهرست محتوا
ویژگی جدید DDR5 RAS
از ویژگیهای مطرح فناوری مذکور به موارد زیر باید اشاره کرد:
کد تصحیح خطای درون تراشهای DRAM (ECC): این قابلیت، امکان تصحیح خطاهای تک بیتی را به صورت درون تراشه فراهم میکند. هنگامی که روند شناسایی خطا به طور یکپارچه در حین اجرای دستورات “خواندن” قبل از انتقال دادهها از DDR5 انجام شود، فشار روی کنترلر کاهش مییابد.
تابع بررسی و پاکسازی خطا (Error check and scrub): این قابلیت به عنوان بخشی از ECC درون تراشه، شامل فرآیند پاکسازی است که در آن حافظهی DRAM به طور خودکار به دنبال خطاهای داخلی خود میگردد و میتواند دادههای تصحیح شده را بازنویسی کند، بنابراین از تجمع خطا بهویژه در ماژولهای DRAM با ظرفیت بالاتر جلوگیری میکند.
انجام عملیات Post-package repair: در نسل DDR4، امکان رفع دائمی خطاها با جایگزینی یک ردیف معیوب با یک ردیف کمکی وجود داشت. فناوری DDR5 با افزودن منابع کمکی بیشتر، این قابلیت را بهبود بخشیده است و همچنین امکان برطرف کردن خطاهای بیشتری را پیش از نیاز به جایگزینی فراهم کرده است.
چرا به RAS حافظه نیاز است؟
یکی از مهمترین جنبههای نگهداری مراکز داده، حفظ حداکثر زمان روشن بودن سرور است. با وجود این، سرورها ممکن است به دلایل مختلفی از جمله مشکلات نرمافزاری، قطعی برق یا خطاهای حافظه با مشکل مواجه شوند. ما سه دسته اصلی از خطاهای حافظه را ردیابی و مدیریت میکنیم که شامل خطاهای قابل اصلاح، خطاهای غیرقابل اصلاح و خطاهای قابل بازیابی میشوند. اینکه کدام خطا قابل اصلاح یا غیرقابل اصلاح است، کاملا به قابلیت کنترلر حافظه بستگی دارد.
خطاهای قابل اصلاح توسط چیپست قابل شناسایی و اصلاح هستند. این خطاها معمولا تکبیتی هستند. تمام سرورهای HPE به لطف پشتیبانی پیشرفته از ECC، قادر به تشخیص و اصلاح خطاهای تکبیتی هستند. در سیستمهای HPE، کاربر در صورت عبور یک ماژول حافظه (DIMM) از آستانهی خطای قابل اصلاح (حداکثر تعداد خطاهای قابل تحمل در یک بازه زمانی مشخص) از طریق چراغهای پنل جلو یا برد سیستم (در صورت وجود) یا گزارش مدیریت یکپارچهی IML اچ پی هشداری دریافت میکند.
خطاهای غیرقابل اصلاح توسط چیپست قابل شناسایی هستند، اما امکان اصلاح آنها وجود ندارد. این خطاها همواره خطاهای حافظهی چندبیتی هستند. این خطاها در گزارش مدیریت یکپارچه (IML) ثبت میشوند و معمولا به یک ماژول حافظهی خاص (DIMM) محدود میشوند. خطاهای غیرقابل اصلاح معمولا بلافاصله منجر به خاموشی یا خرابی سیستم میشوند. در برخی موارد، سیستم عامل و پردازندههای پیشرفته (پردازندههای Intel® Xeon® Platinum و Intel® Xeon® Gold) نصب شده روی سرور قادر به مدیریت خطاهای غیرقابل اصلاح هستند تا سرور بتواند به کار خود ادامه دهد. ما این خطاها را خطاهای قابل بازیابی مینامیم. برای جزئیات بازیابی خطا باید اطلاعات مربوط به سیستمعاملی که از آن استفاده میکنید را بررسی کنید.
انواع خطاهای حافظهی DRAM
خطاهای حافظهی DRAM عموما در دو نوع مختلف رخ میدهند: خطاهای سخت و خطاهای نرم.
به طور معمول، خطاهای سخت نشاندهندهی مشکلی در خود ماژول حافظه (DIMM) هستند. اگرچه سرور توانایی اصلاح خطاهای سخت را دارد و اجازه نمیدهد دادهها از دست بروند یا عملکرد سیستم متوقف شود، اما همچنان نشاندهندهی یک مشکل سختافزاری هستند. خطاهای سخت معمولا باعث میشوند یک ماژول حافظه از آستانهی خطای قابل اصلاح سرورهای اچ پی تخطی کند. در بیشتر موارد، کاربر در مورد این خطاها هشداری دریافت میکند.
خطاهای نرم نشاندهندهی هیچ مشکلی در ماژول حافظه (DIMM) نیستند. این خطاها زمانی رخ میدهند که داده و یا بیتهای ECC روی ماژول اشتباهی در حافظه نوشته شده باشند. بنابراین، پس از اصلاح داده و یا بیتهای ECC روی DIMM، این خطا برطرف میشود. خطاهای نرم معمولا باعث نمیشوند یک ماژول حافظه از آستانهی خطای قابل اصلاح سرورها عبور کند و بنابراین، نشاندهندهی یک مشکل سختافزاری نیستند.
با اینحال، نکته مهمی که باید به آن دقت کنید این است که هرگونه خطایی، اگر به درستی مدیریت نشود، در نهایت میتواند منجر به خاموشی سیستم شود. در روزهای اولیه عرضه سرورها، ECC راهکاری قدرتمند برای رفع اکثر خرابیهای حافظهی رم (DRAM) به شمار میرفت و عملکرد بالایی داشت. با این حال، سرورهای پیشرفته مشکلات مخصوص به خود را دارند، بنابراین برای حفظ پایداری و زمان فعالیت مورد انتظار سرور، ما نیازمند ویژگیهای پیشرفتهتری هستیم که RAS در اختیار ما قرار میدهد. این نکته مهم است که بدانیم اگر بتوانیم یک خرابی بحرانی را شناسایی و برطرف کنیم، مانع از خاموش شدن سیستم شویم. همچنین، فناوری RAS حافظه میتواند ماژول حافظهی رم (DRAM) روی یک DIMM که دارای خطاهای نرم زیادی بوده است را شناسایی کند و قبل از اینکه سرور دچار خرابی سخت شود، پیشنهاد تعویض ماژول معیوب را بدهد.
بیشتر بدانید
فناوریهای RAS حافظه در سرورهای HPE ProLiant/Synergy/Blade
اکنون اجازه دهید عملکرد فناوریهای پر کاربردی RAS حافظه را مورد بررسی قرار دهیم.
آستانه خطای سریع اچ پی (HPE Fast Fault Tolerance)
Fast Fault Tolerance چیست؟ آستانه خطای سریع اچ پی یک ویژگی RAS Memory است که برای اولین بار در سرورهای نسل دهم معرفی شد و همچنان در سرورهای نسل یازدهم توسط پردازندههای مقیاسپذیر زئون اینتل پشتیبانی میشود.
سرورهایی که با HPE SmartMemory و آستانه خطای سریع اچ پی پیکربندی شدهاند، یک لایه حفاظت اضافی در برابر توقف عملکرد سرور و خرابیهای سرور ارائه میدهند. آستانه خطای سریع اچ پی، نسخهی بهبودیافتهی مکانیزم تصحیح تطبیقی دوتایی دستگاه DRAM (ADDDC) مخفف Adaptive Double DRAM Device Correction، حاصل همکاری مشترک شرکت اینتل و اچ پی است.
این ویژگی دارای نواحی کمکی (بخشی از حافظه که فقط برای جایگزینی نواحی معیوب حافظه اختصاص داده شده است) و گزینههای بیشتری برای نگاشت بخشهای خراب حافظه است. این امر منجر به قابلیت اطمینان و در دسترسبودن حافظه به شکل کارآمدی، بهتر از آنچه سایر برندهای این صنعت تنها با استفاده از ADDDC ارائه میدهند، در اختیار مصرفکنندگان قرار میدهد.
ویژگیها Fast Fault Tolerance
در نسلهای گذشتهی سرورهای HP، پیشرفتهترین فناوری حفاظت از حافظه در سرورهای پرولیانت اچ پی، مکانیزم DDDC مخفف Double Device Data Correction بود. بزرگترین مشکل فناوری مذکور این بود که باید در هنگام راهاندازی سیستم فعال میشد و در صورت فعال بودن، به طور قابل توجهی توان عملیاتی حافظه را کاهش میداد. مشتریان مجبور بودند بین انعطافپذیری و عملکرد یکی را انتخاب کنند. آستانه تحمل خطای سریع اچ پی نسبت به DDDC بهبود قابل توجهی را ارائه میدهد، زیرا مزایای عملکردی SDDC و دسترسپذیری DDDC را ترکیب میکند. این ویژگی به سرور اجازه میدهد با عملکرد کامل حافظه راهاندازی شود و تنها بخشهای کوچکی (بانکها) از حافظه را در صورت لزوم برای اصلاح خرابیها وارد حالت هماهنگ (lockstep) کند که منجر به عملکرد بهتری نسبت به DDDC میشود. با این حال، هنگامی که بخش معیوب بزرگتر از یک بانک باشد، ممکن است عملکرد کاهش پیدا کند.
نکته
آستانه تحمل خطای سریع اچ پی تا دو خرابی DRAM را تحمل میکند (شناسایی و اصلاح).
این ویژگی RAS، انعطافپذیری و دسترسپذیری DDDC را با عملکرد SDDC ترکیب میکند.
حداقل الزامات
باید حداقل در هر کانال حافظه پر شده برای هر پردازنده، حافظه دارای قابلیت dual rankوجود داشته باشد. همچنین، فقط از HPE SmartMemory های 2R ویا 4R میتوان استفاده کرد.
خرید سرور اچ پی dl 380 g11 در نتسا
چگونه Fast Fault Tolerance را فعال کنیم؟
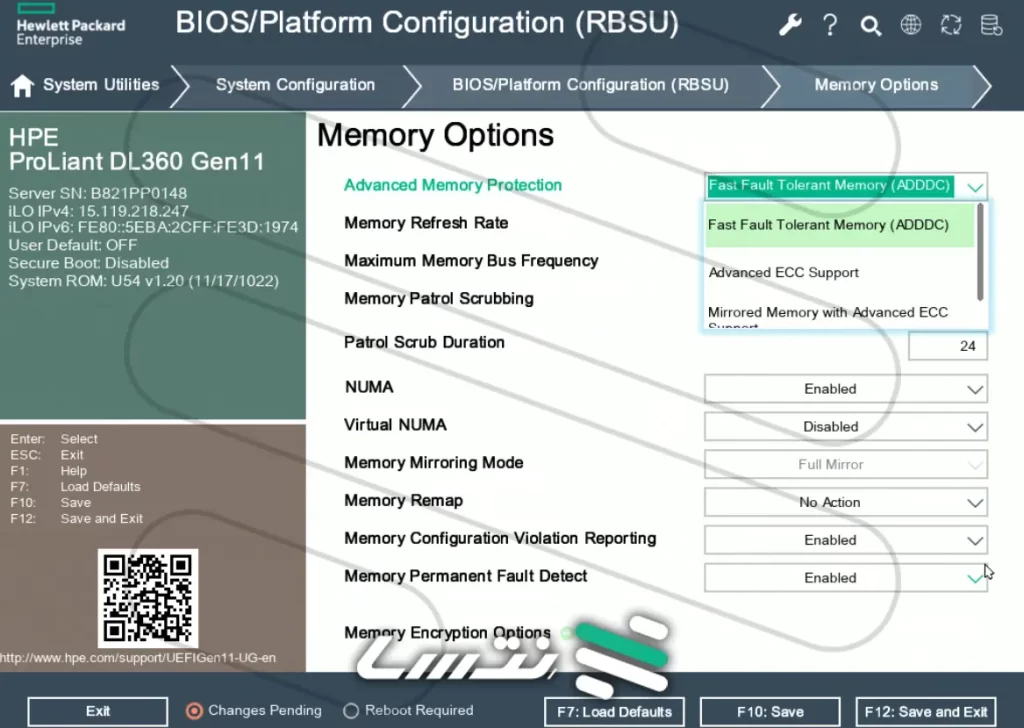
ویژگی مذکور به طور پیشفرض فعال است، زمانی که پروفایل “ماموریت بحرانی” در ابزار راهاندازی مبتنی بر ROM (RBSU) انتخاب شود. صرف نظر از ویرایش ROM، ویژگی فوق را همیشه میتوان در سرورهای نسل یازدهم پرولیانت اچ پی در زمان خرید (با مراجعه به مشخصات فنی مختصر پلتفرم) فعال کرد. همچنین، ویژگی مذکور را میتوان از طریق RBSU یا API مبتنی بر REST در هر سرور نسل یازدهم پرولیانت فعال یا غیرفعال کرد. الزمات پیکربندی آستانه تحمل خطای سریع اچ پی برای هر سری سرور ممکن است متفاوت باشد، اما این ویژگی به پشتیبانی سیستمعامل یا نرمافزار خاصی به جز سیستم پایهای ورودی/خروجی (BIOS) نیاز ندارد. همانطور که در شکل 1 نشان داده شده است، برای فعال کردن این قابلیت، باید از صفحهی ابزارهای سیستمی، به مسیر زیر بروید:
System Configuration > BIOS/Platform Configuration (RBSU) > Memory Options > Advanced Memory Protection
نکات فنی برای فعالسازی Fast Fault Tolerance
فعالسازی آستانه تحمل خطای سریع اچ پی که یک قابلیت برای افزایش قابلیت اطمینان Memory RAS است، در حال حاضر نیازمند اجرای سرور در حالت «صفحهبسته» (closed-page) است. این حالت میتواند باعث کاهش جزئی در سرعت انتقال اطلاعات (throughput) برای برخی از حجمهای کاری شود. بهطور کلی، انتظار نمیرود حالت صفحهبسته تاثیر قابل توجهی بر عملکردِ دسترسی تصادفی به حافظه (مانند پایگاهدادههای SQL) داشته باشد. با این حال، بر عملکردِ دسترسی ترتیبی به حافظه (مثل جریانهای انتقال داده) تاثیر منفی خواهد گذاشت.
همچنین، در صورت خرابی یک ماژول حافظهی رم (DRAM)، افت جزئی در سرعت انتقال اطلاعات رخ میدهد. اما این کاهش تنها در محدودهی بسیار کوچکی از حافظه (معمولا به اندازهی یک بانک حافظه) که تحت تاثیر قرار گرفته است، اتفاق میافتد. از آنجایی که به این بخش از حافظه در حالت هماهنگ (lockstep) به ندرت دسترسی پیدا میشود، انتظار افت قابل توجهی برای دسترسی تصادفی به حافظه وجود ندارد. اما اگر از قفل مجازی در سطح ردیف (rank-level) استفاده کنید یا برنامهای به طور مداوم به این بخش از حافظه دسترسی پیدا کند تا زمانی که ماژول رم معیوب تعویض شود، افت عملکرد میتواند قابل توجه باشد. کاهش کلی در سرعت انتقال اطلاعات ناشی از تحمل خطای سریع اچ پی برای بسیاری از کاربران ناچیز است، اما این امر به نوع برنامهی در حال اجرا، اندازهی بخش آسیبدیده حافظه و پیکربندی حافظهی سرور بستگی دارد.

پشتیبانی از تصحیح خطای پیشرفته (ECC)
تصحیح خطای پیشرفته (ECC) حالت پیشفرض برای محافظت از حافظه در سرورهای اچ پی است. تصحیح خطای استاندارد میتواند خطاهای تکبیتی حافظه را اصلاح کند و خطاهای چندبیتی را تشخیص دهد. هنگامی که خطاهای چندبیتی با استفاده از تصحیح خطای استاندارد شناسایی شوند، این خطا، سیگنالی برای سرور ارسال میکند که باعث توقف عملکرد آن میشود. تصحیح خطای استاندارد هنوز در برخی از پردازندهها مورد استفاده قرار میگیرد.
تصحیح خطای پیشرفته برای بیش از دو دهه به عنوان روش پیشفرض حل مشکلات در سرورهای اچپیئی به کار رفته است. این روش نه تنها از سرور در برابر خطاهای تک بیتی محافظت میکند، بلکه در برابر برخی خطاهای چند بیتی حافظه نیز مکانیزمهای حفاظتی ارائه میکند – به طور خاص خطاهایی که درون یک تراشهی DRAM واحد رخ میدهند.
تصحیح خطای پیشرفته میتواند هم خطاهای تک بیتی و هم خطاهای ۴ بیتی را اصلاح کند، به شرطی که تمامی بیتهای معیوب روی یک ماژول رم (DIMM) قرار گرفته باشند. تصحیح خطای پیشرفته نسبت به تصحیح خطای استاندارد، حفاظت بیشتری ارائه میدهد؛ زیرا امکان اصلاح خطاهای خاصی از حافظه وجود دارد که در صورت عدم توجه به آنها و برطرف نکردن آنها در نهایت منجر به خرابی سرور میشوند. سرور با استفاده از فناوری پیشرفتهی تشخیص خطای حافظهی اچپیئی، زمانی که یک ماژول رم رو به خرابی میرود و احتمال خطای غیرقابل اصلاح در آن افزایش مییابد، هشدار میدهد.
حداقل الزامات
برای پشتیبانی از تصحیح خطای پیشرفته، هیچ قانون خاصی برای توزیع حافظه یا تنظیمات RBSU وجود ندارد. این قابلیت به طور پیشفرض روی پلتفرم Eagle Stream فعال است.
نحوه فعالسازی پشتیبانی از تصحیح خطای پیشرفته
پشتیبانی از تصحیح خطای پیشرفته، حالت پیشفرض برای محافظت پیشرفته از حافظه در RBSU است. شکل ۲ گزینههای مختلف حافظه را نشان میدهد.
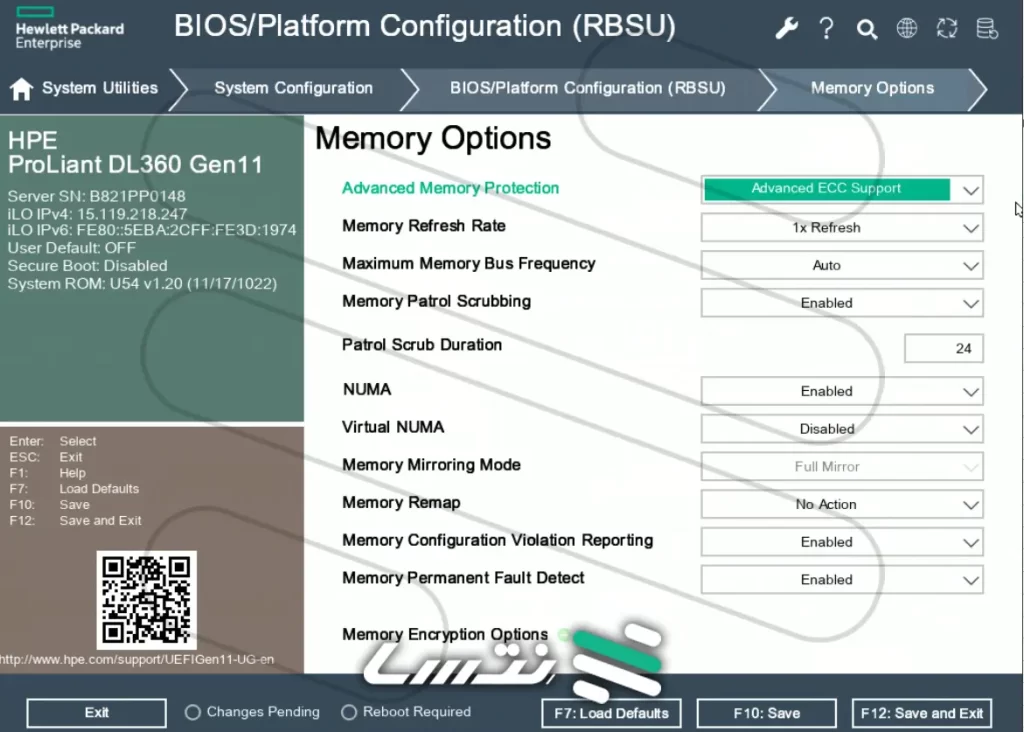
نکات فنی برای فعالسازی Advanced ECC
اگرچه تصحیح خطای پیشرفته (ECC) از سیستم در برابر خرابی محافظت میکند، اما این قابلیت تنها زمانی میتواند به طور قابل اطمینان خطاهای چند بیتی را اصلاح کند که این خطاها درون یک تراشهی DRAM واحد رخ دهند. تصحیح خطای پیشرفته، ویژگی failover را ارائه نمیکند. در نتیجه، در صورت بروز خرابی حافظه، سیستم باید قبل از تعویض حافظهی معیوب، خاموش شود. استفاده های تکنولوژی Memory RAS در سرورهای پرولیانت و بلید و سینرژی که از پردازندههای مقیاسپذیر Intel Xeon استفاده میکنند، سه سطح مکانیزم پیشرفته محافظت از حافظه با قابلیت تحمل خطا (از جمله آستانه خطای سریع اچ پی) را ارائه میدهند که برای برنامههای کاربردی که دسترسپذیری (availability) برای آنها حرف اول را میزند، حائز اهمیت است.
