بررسی کارت گرافیک های TESLA K40 و TESLA K80

فهرست محتوا
کارت گرافیک های NVIDIA
تاریخچه شرکت انویدیا
انویدیا یک شرکت آمریکاییست که پیشگام در تکنولوژی های طراحی و تولید پردازنده های کارت های گرافیک یا GPU برای بازارهای طراحان بازی های حرفه ای و همچنین System on Chip Units(SoCs) برای بازارهای تولیدات موبایل و خودروها میباشد. اولین خط تولید GPU ها با نام GeForce و در رقابت با محصولات پیشرفته برند Advanced Micro Devices (AMD) به بازار عرضه می شد.
از سال 2014، Nvidia Corporation تجارت خود را با تمرکز بیشتر بر روی سه بازار متنوع و مهم دنیا گسترش داد: Gaming، الکترونیک در حوزه خودروسازی و موبایل ها.
علاوه بر تولید GPU، انویدیا قابلیت پردازش موازی برای محققان و دانشمندان را فراهم آورده که به آنها امکان اجرای اپلیکیشن های کاربردی با کارایی بالا می دهد. این برنامه های حیاتی در سایت های Supercomputing با مقیاس پردازش بالا که توسط floating-point operations per second (FLOPS) اندازه گیری می شود، مستقر شده اند. این شرکت اخیراً، توجه خود را به بازار محاسباتی موبایل که پردازنده های موبایل Tegra را برای تلفن های هوشمند و تبلت ها، سیستم های ناوبری خودرو و سرگرمی تولید میکنند، منتقل کرده است. علاوه بر AMD، رقبای دیگر این شرکت که میتوان به آن اشاره کرد شامل: Intel، Qualcomm و Arm می باشند.
انواع کارت گرافیک انویدیا

مهم ترین محصولات تولید شده توسط Nvidia، کارت گرافیک های آن است که شامل دسته بندی های زیر می باشند:
- سری GeForce مناسب برای Gaming
- سری Quadro مناسب برای کارهای حرفه ای کامپیوتری و تولید محتوای دیجیتالی برای workstation و کارهای تحقیقاتی
- سری Tesla مناسب برای سرورها
بررسی کارت گرافیک های TESLA K40 و TESLA K80
ممکن است NVIDIA Tesla را به عنوان سری محصولات بردهای بهینه سازی شده شتابدهنده GPU شناخته باشید که هدف کلی تولید آن برای محاسبات با کارایی بالا باشد. ولی این سری محصولات انویدیا برای محاسبات موازی علمی، شرکت های مهندسی و تکنیکال استفاده می شوند و برای عملکرد بالا در ابر رایانه ها، کلاسترها و Workstationها طراحی شده اند. اما تنها بوردهای GPU نیستند که تسلا را تبدیل به یک راهکار محاسباتی عالی کرده است. ترکیبی از سریعترین شتابدهنده های GPU در جهان، مدل CUDA parallel computing که بطور گسترده ای استفاده میشود و اکوسیستم جامع توسعه دهندگان نرم افزار، فروشندگان نرم افزار و سیستم های OEM دیتا سنتر، تسلا را به پیشروترین پلتفرم در تسریع آنالیز داده ها و محاسبات علمی تیدیل کرده است.
سیستم عامل محاسبه تسریع شده تسلا یا Tesla Accelerated Computing Platform ویژگی های مدیریت پیشرفته سیستم و فناوری ارتباطات تسریع داده شده را فراهم کرده و توسط نرم افزار مدیریت زیرساخت، پشتیبانی می شود. این قابلیت ها متخصصان HPC را قادر ساخته به راحتی بر عملکرد شتاب دهنده های تسلا در مراکز دیتا نظارت و مدیریت داشته باشند. اپلیکیشن های Tesla قدرت گرفته از CUDA ها هستند که پلتفرم محاسباتی موازی NVIDIA و مدل برنامه نویسی را پشتیبانی میکند و یک مجموعه کامل از ابزارهای توسعه دهنده کارآمد در اختیار برنامه نویسان قرار می دهد.
در این مقاله مروری بر طیف گسترده ای از فناوری ها، ابزارها و مؤلفه های سیستم عامل محاسبه تسریع شده تسلا که در دسترس توسعه دهندگان برنامه است، ارائه می دهیم.
تسلا با تمامی پلتفرم های سرور انطباق پذیر است x86، ARM و POWER

تسلا تنها پلتفرم محاسباتی تسریع شده بر روی سیستم های دارای انواع اصلی معماری پردازنده ها است از جمله: x86 ،ARM64 و POWER. اما برای اجرا بر روی GPU تسلا، نیازی به نصب امکانات HPC شخصی خود ندارید و اپلیکیشن های مبتنی بر Cloud می توانند از CUDA برای شتاب در هزاران GPU تسلا موجود در کلود آمازون بهره گیرند.
پیشنهاد مطالعه: کاربرد رایانش ابری
توسعه بیشتر در GeForce
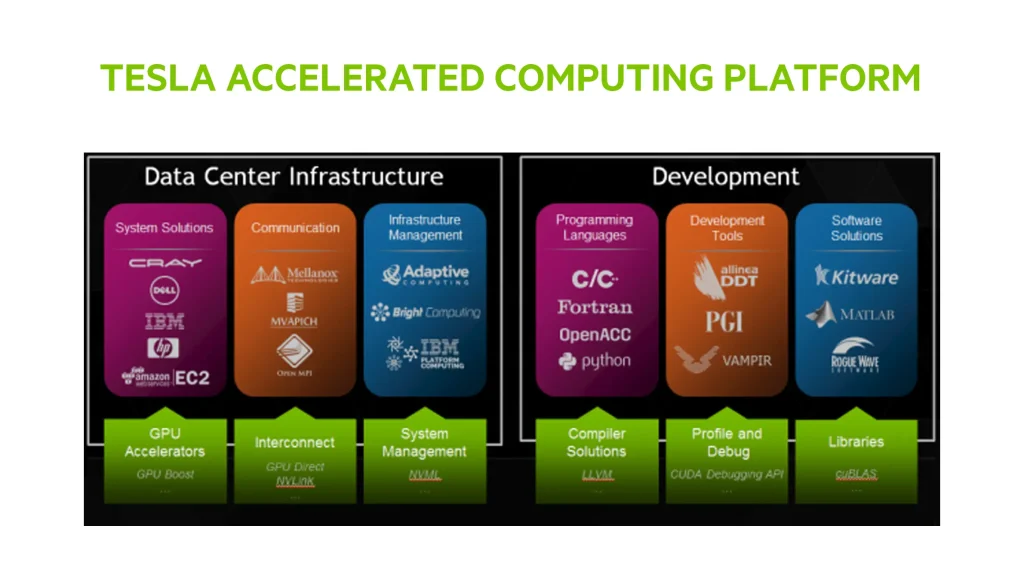
پلتفرم محاسباتی CUDA parallel توسط کلیه GPU های انویدیا پشتیبانی می شود، از پردازنده های استفاده شده در تلفن های همراه تا سریعترین پردازنده های گرافیکی استفاده شده در دسکتاپ GeForce، تا پردازنده های سطح بالای Quadro و Tesla. این بدان معناست که میتوانید برنامه های کاربردی با کارایی بالا که از CUDA در لپ تاپ های GeForce یا Apple iMac یا Macbook Pro استفاده می کنند را توسعه داده و آنها را روی سریعترین GPUهای تسلا که در High-end Workstationها یا حتی در Cluster ها یا سوپر کامپیوترها استفاده شده است گسترش دهید.
ویژگی های ارائه شده در پلتفرم قدرتمند مدیریت سیستم Tesla
پلتفرم تسلا شامل ابزارهای وسیع و متنوع مدیریت سیستم برای ساده سازی مدیریت GPU، نظارت بر سلامت و سایر معیارها و بهبود استفاده از منابع و بهره وری می باشد. بسیاری از محبوب ترین و قدرتمندترین ابزارهای مدیریت کلاستر و زیرساخت موجود در صنعت HPC، از APIهای موجود در مدیریت سیستم NVIDIA برای پشتیبانی GPUها استفاده میکنند، از جمله میتوان به IBM Platform HPC، PBS Workها، Bright Cluster Manager، Ganglia، Adaptive Computing Moab HPC Suite و TORQUE Resource Manager اشاره کرد.
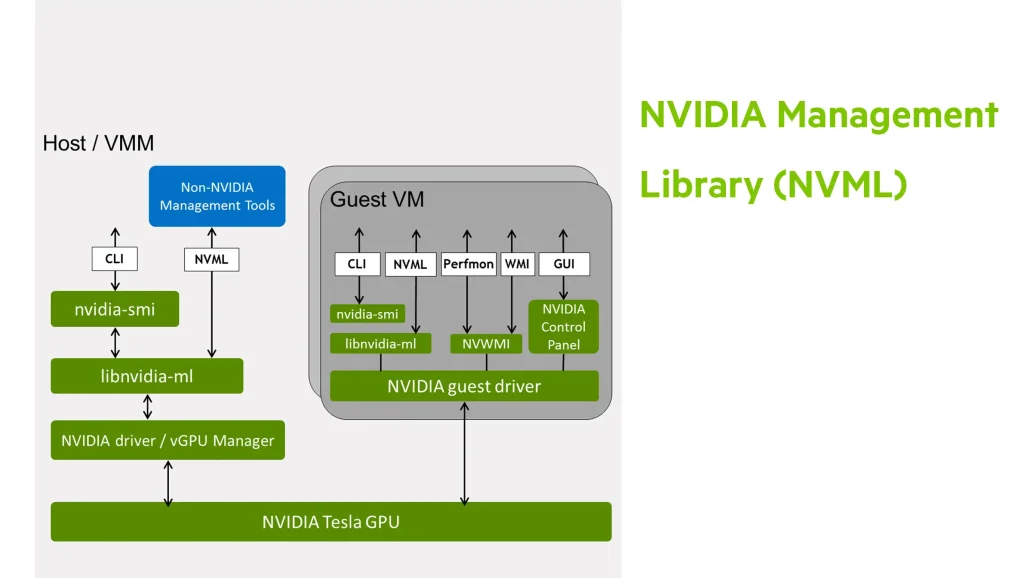
NVIDIA Management Library (NVML) یک GPU تعیین شده برای مانیتورینگ و مدیریت API با استفاده از رابط های C و Python می باشد. توسعه دهندگان و سرپرستان سیستم ها می توانند از NVML برای نظارت بر دما، سرعت فن، میزان قدرت board، میزان مصرف منابع، مشخص کردن میزان خطاهای ECC، clock speedها (اورکلاک در GPUها) و معیارهای دیگر استفاده کنند و حالت های مختلف GPU مانند ECC، محاسبه اختصاصی پردازش، پایداری درایو و power capping را بررسی کنند.
nvidia-smi یک ابزار تحت فرمان cross-platform با قابلیت های مشابه NVML میباشد که نظارت و مدیریت GPU را در سطح Node فراهم می کند.
NVIDIA-Healthmon یک ابزار تشخیصی برای مدیران IT برای تشخیص و عیب یابی مشکلات رایج GPU می باشد که از ان جمله میتوان به مشکلات سخت افزاری و نرم افزاری، پیکر بندی و سایر موارد دیگر اشاره کرد.
NVIDIA Documentation Portal این پورتال منابع و API های جامع کاربردی را ارائه می کند.
Tesla و Quadro ارائه کننده تکنولوژی شتاب در ارتباطات
پلتفرم تسلا از پهنای باند بالا، Latency پایین در ارتباطات برای کلاسترهایی که با GPU شتابدهی شده اند و workstation ها پشتیبانی میکند. با استفاده از GPUDirect، آداپتورهای شبکه 3rd party، درایوهای SSD (بررسی درایوهای SSD HPE) و سایر دستگاه ها میتواند بصورت مستقیم عملیات خواندن و نوشتن را بر روی هاست CUDA و حافظه دستگاه انجام دهند. GPUDirect کپی های غیر ضروری حافظه سیستم را حذف میکند، بطور چشمگیری سربار CPU را کاهش داده و منجر به کاهش زمان تاخیر می شود و در نتیجه باعث بهبود عملکرد قابل توجه در زمان انتقال داده ها برای برنامه های در حال اجرا در محصولات NVIDIA Tesla™ و Quadro™ می شود. پیاده سازی CUDA-aware MPI مانند MVAPICH و OpenMPI شتاب در انتقال پیام را میسر ساخته که از انتقال کارآمدتر بین حافظه GPU در سراسر cluster node ها پشتیبانی میکند.
پشتیبانی CUDA از تمامی بسترهای نرم افزاری Tesla
پایه و اساس توسعه برنامه های کاربردی نرم افزاری که از پلتفرم تسلا بهره می برند CUDA، پلتفرم محاسبات موازی NVIDIA و مدل برنامه نویسی موازی می باشد. CUDA مسیری انعطاف پذیر برای شتاب اپلیکیشن، در اختیار توسعه دهندگان قرار میدهد و از چندین رویکرد توسعه نیز پشتیبانی میکند. ساده ترین روش اینست که معمولاً از GPU-accelerated library ها برای بدست آوردن شتاب بصورت drop-in برای linear algebra، تبدیل سریع Fourier، حل کننده های معادلات خطی و انواع دیگر محاسبات بهره می برند. برای سرعت بخشیدن به کدهای C، C++ و Fortran موجود، برنامه نویسان می توانند از دستورالعمل های OpenACC compiler برای موازی سازی Loopها بطور اتوماتیک استفاده کنند. همچنین برای عملکرد بالاتر بر روی طیف وسیع تری از کدها، توسعه دهندگان می توانند الگوریتم های موازی خود را طراحی کرده و آنها را به زبان های برنامه نویسی که از قبل می شناسند، پیاده سازی کنند.
در ادامه به بررسی دو مدل از پرطرفدارترین کارت های مورد استفاده بر روی انواع سرور HP در سری Tesla خواهیم پرداخت.
کارت گرافیک TESLA K40

کاربردی ترین مدل GPU در انویدیا تسلا که برای سرعت انتقال بالاتر و ارائه عملکرد محاسباتی کارآمدتر طراحی شده است
با معرفی شتابدهنده های Tesla K40 GPU می توانید مدلهای علمی بزرگ را بر روی حافظه 12 گیگابایت خود با سرعت بالایی اجرا کنید، همچنین قادر به پردازش داده های دوبرابر بزرگتر می باشید و ایده آل برای آنالیز Big Data ها می باشد. علاوه بر آن بر عملکرد CPUها با بهره گیری از ویژگی GPUBoost تا حداکثر 10 برابر اثر خواهد داشت و منجر به تبدیل قدرت Headroom به تقویت عملکرد User-controlled می گردد و در نتیجه کارایی فوق العاده ای را در سرورها ارائه میکند.
مشخصات فنی Tesla K40 – PNY
Memory Size: 12 GB GDDR5
Memory Interface: 384-bit
Memory Bandwidth (ECC off)): 288 GB/s
CUDA Cores: 2880
System Interface: PCI Express 3.0 x16
Processor core clock: 745 MHz
Memory clock: 3.0 GHz
Cache: L1 & L2
Maximum Consumption: 235 W
Number of GPUs: 1 × GK110B
Energy Star Enabling: Yes
Conformité Européenne (CE): Yes
Thermal Solution: Ultra-quiet Active Fansink
Form Factor: 110 mm (H) × 265 mm (L) – Dual Slot, Full-Height
Connectors: 1 × 6-pin PCI Express power connectors – 1 × 8-pin PCI Express power connectors
SMX: Yes
Dynamic Parallelism: Yes
Hyper-Q: Yes
NVIDIA GPU Boost: Yes
GPU Computing Applications: Reservoir simulation – CAE (structural analysis) – Molecular dynamics, Numerical analytics – Computational visualization (ray tracing)
Peak double precision floating point performance: 1.43 Tflops
Peak single precision floating point performance: 4.29 Tflops
System: Workstations
Compatible with: Windows Vista, Windows 7 – 64-bit – Linux 32-bit and 64-bit – Fedora 12 – RHEL 5.4 Desktop – Ubuntu 9.10 Desktop – RHEL 4.8 Desktop (64-bit only) – RHEL 6 – OpenSUSE 11.2 – SLED 11
کارت گرافیک TESLA K80

با بالاترین عملکرد جهانی با دارا بودن شتابدهنده Dual-GPU که برای طیف وسیعی از اپلیکیشن ها طراحی شده است، از Machine Learning تا تجزیه و تحلیل داده ها برای علوم تحقیقاتی و محاسباتی با کارایی بالا (HPC) پشتیبانی میکند
Tesla K80 Dual-GPU Accelerator از پرچمداران جدید در سری تسلا برای تسریع در پلتفرم محاسباتی می باشد، پلتفرم پیشرو در زمینه تسریع تجزیه و تحلیل داده ها و محاسبات علمی از قابلیت های مهم این محصول می باشد. این ترکیب سریعترین شتابدهنده GPU در جهان، از مدل CUDA Parallel Computing بهره گرفته است و یک اکوسیستم کامل برای توسعه دهندگان نرم افزار و فروشندگان، مراکز داده و OEM ها فراهم کرده است.
Tesla K80 ظرفیتی دو برابری در عملکرد و پهنای باند حافظه نسبت به نسل قبلی خود K40 GPU ارائه کرده است. Tesla K80 توانسته قدرت پردازنده فعلی را تا 10 برابر افزایش داده و در مقایسه با CPUهای رقبا و شتابدهنده های هم رده خود با صدها ابزار پیچیده تحلیلی و برنامه های جامع و محاسبات علمی، عملکرد بهتری ارائه کند.
پیشگام در عملکرد برای تحقیقات علمی، آنالیز اطلاعات و Machine Learning
برای پاسخگویی به سخت ترین چالش های محاسباتی، از Astrophysics گرفته تا تجزیه و تحلیل داده ها از طریق ژنومیک و شیمی کوانتومی، طراحی شده است. همچنین انجام کارهای پیشرفته Deep Learning، که یکی از مهم ترین بخش های در حال رشد در یادگیری ماشینی می باشد را بهینه سازی کرده است.
مشخصات فنی Tesla K80 – PNY
Memory Size: 24GB GDDR5 (12 GB per GPU)
Memory Interface: 384-bit
Memory Bandwidth (ECC off)): 480GB / s (per board) – 240 GB / s (per GPU)
CUDA Cores: 4992
System Interface: PCI Express 3.0 x16
Processor core clock: Base clock: 560 MHz – Boost clock: 562 – 875 MHz
Memory clock: 2.5 GHz
Hidden: L1 and L2
Max. Consumption: 300 W
Number of GPUs: 2 × GK210
Energy Star Enabling: Yes
European conformity (CE): Yes
Thermic Solution: Passive
Format: 111.150 mm (H) × 267 mm (L) – Dual Slot, Full-Height
Connectors: 1 × 8-pin CPU power connectors (2 x 8-pin PCIe to single 8-pin CPU adapter included)
SMX: Yes
Dynamic Parallelism: Yes
Hyper-Q: Yes
GPU Computing Applications: Reservoir simulation – CAE (structural analysis) – Molecular dynamics, Numerical analytics – Computational visualization (ray tracing)
Peak double precision floating point performance: 2.91 Tflops (GPU Boost Clocks) – 1.87 Tflops (Base Clocks)
Peak single precision floating point performance: 8.74 Tflops (GPU Boost Clocks) – 5.6 Tflops (Base Clocks)
System: Servers
Compatible with: Windows 64-bit – Linux 64-bit
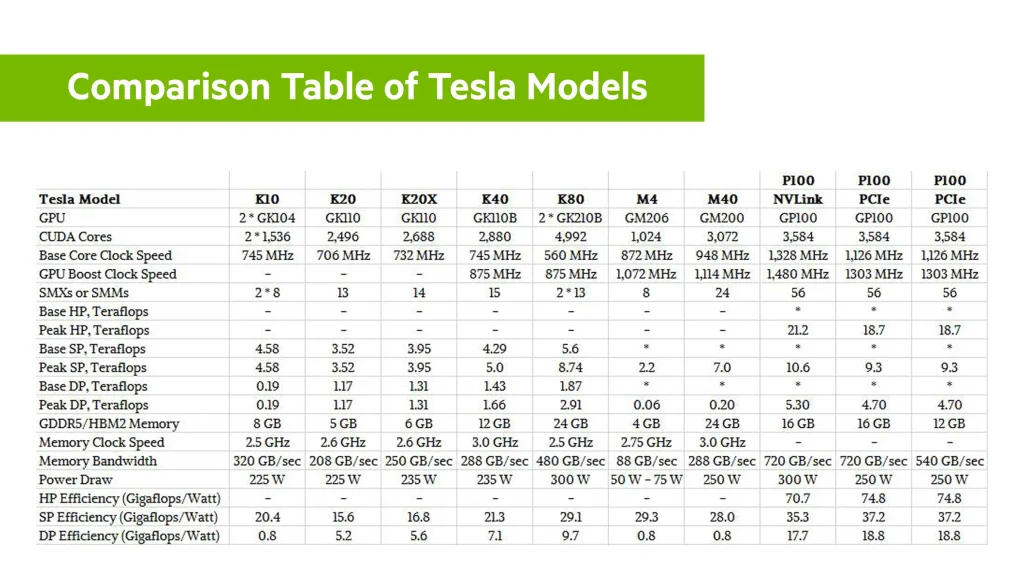
جدول مقایسه مدل محصولات تسلا: